
Cieľom zadania je priblížiť metodiku, akou sa hľadajú a zneužívajú zraniteľnosti v reálnych aplikáciach. K dispozícii bude HTTP server napísaný v jazyku C, ktorý obsahuje rôzne zraniteľnosti (frontend webovej aplikácie, ktorý beží na serveri je implementovaný v Pythone pomocou frameworku Flask; v tomto zadaní nás to však nebude zaujímať). Hlavnou úlohou zadania je nájsť zraniteľnosť na HTTP serveri (budeme sa zaoberať zraniteľnosťami typu stack overflow), ktorého zdrojový kód je k dispozícii a využiť túto zraniteľnosť na spustenie reverse shellu, čím ako útočníci získate kontrolu nad sytémom. Výsledkom zadania bude skript, ktorý skonštruuje špeciálne vytvorený paket a odošle ho na HTTP server; chyba v implementácii však spôsobí spustenie reverse shellu. V tomto zadaní sa bude pracovať s vypnutou NX ochranou, čo znamená že dáta, ktoré obsahuje proces na zásobníku bude možne spustiť, t.j. keď programové počítadlo (IP) skočí na adresu nachádzajúcu sa na zásobníku, procesor bude tieto dáta interpretovať ako inštrukcie a pokúsi sa ich vykonať.
Inštalácia servera
HTTP server bude bežať na 64 bitovom operačnom systéme Debian, ktorý ste si pripravili počas prác na prvom zadaní. Ako prvý krok je nutné nainštalovať niektoré balíčky a naklonovať repozitár:
sudo apt update
sudo apt upgrade
sudo apt install gcc git build-essential openssl libssl-dev execstack python-pip
sudo python -m pip install flask sqlalchemy
git clone https://github.com/petersvec/bispp_lab_01
cd ./bissp_lab_01/
O tom ako skompilovať a spustiť server sa možno dozvedieť viac na githube. Funkčnosť servera môžete otestovať v prehliadači. Pripomíname, že v tomto zadaní je potrebné spúšťať verziu s vypnutým NX. V repozitári sa potom nachádzajú všetky zdrojové kódy, ktoré môžete použiť pri vývoji exploitu. Pred začatím vývoja odporúčame preštudovať si zdrojový kód (nie úplne do hĺbky), aby bolo jasné aké komponenty obsahuje server, kde a ako sa spracúva obsah prichádzajúcich paketov a pod.
Príprava prostredia na vývoj exploitu
Pracovať na exploite môžete kvôli pohodliu aj priamo na virtuálke kde beží server, avšak potom by bolo vhodné demonštrovať funkčnosť exploitu aj z iného počítača. V systéme na ktorom budete pracovať je vhodné si nainštalovať nasledujúce nástroje:
sudo python -m pip install pwntools
Poznámka: vyššie spomínané nástroje sú len odporúčané, t.j. ak uznáte za vhodné, môžete si zvoliť aj iné. V takom prípade však nezabudnite do dokumentácie zahrnúť ich popis, odkaz na stiahnutie, postup inštalácie a pod.
V tomto momente by ste mali mať pripravené všetky potrebné nástroje na začiatok vývoja. V repozitári s HTTP serverom máte pripravený template Python skriptu (aj s nejakými pomôckami) do ktorého doplníte váš kód. Šablóna vytvorí HTTP GET request na stránku index.html a odošle ho na localhost:80 (parametre môžete ľubovoľne zmeniť). Skript sa jednoducho spustí:
./exploit.py
Nástroj Venom funguje tak, že po vygenerovaní kódu sa spustí konzola a čaká kým sa spustí shellcode. Ak sa vám úspešne podarí implementovať exploit a proces HTTP servera spustí vygenerovaný shellcode, vo Venom konzole získate reverse shell na systém, v ktorom daný proces beží.
POZOR: je absolútne nevyhnutné aby ste na počítači, kde beží HTTP server vypli ASLR, ochranu proti exploitácii. V prídade reštartu počítača je nutné ju vypnúť znova (na tento krok sa ľahko zabudne a je častým dôvodom prečo exploit nefunguje). Príkazy:
su
echo 0 > /proc/sys/kernel/randomize_va_space
Ako postupovať
Pri exploitácii sa vždy hodí poznať základy assembleru, avšak nie je to nutné. Keďže budeme exploitovať pretečenie zásobníka, je vhodné minimálne poznať ako vyzerá prológ a epilóg funkcie, aké registre sa používajú na prácu so zásobníkom a ako vyzerá zásobník počas volania funkcie. Najdôležitejšie je však pochopenie, akým spôsobom funguje inštrukcia RET, ktorá načíta do registra RIP (instruction pointer na x64 architektúre) hodnotu na vrchu zásobníka a vykonávanie programu sa presunie na toto miesto (ak sa nám podarí ovplyvniť hodnotu na vrchu zásobníka v tom momente, získali sme kontrolu nad tokom programu). Pre lepšie pochopenie odporúčam prejsť si nasledujúci tutoriál na jednoduché pretečenie zásobníka (obzvlášť dôležité je poznanie maximálnej možnej adresy na 64 bitových systémoch). Tutoriál poslúži aj na precvičenie si práce v GDB debuggeri s Peda rozšírením. Medzi užitočné príkazy patrí krokovanie, nastavenie breakpointu či sledovanie obsahu adries.
Po spustení servera sa vytvorí viacero procesov (ich popis možno nájsť na githube). Vo výpise môžeme vidieť aké PID majú jednotlivé procesy.
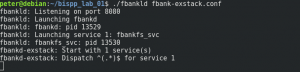
To nám pomôže ak chceme ladiť niektorý z týchto procesov pomocou GDB. Ak chceme napríklad ladiť proces fbankd, GDB spustíme pomocou nasledujúceho príkazu:
gdb -p 1359
Treba si však uvedomiť že niektoré tieto procesy vytvárajú ďalšie detské procesy a GDB v štandardnom móde ostáva vždy v rodičovskom procese. Ak chceme následovať vykonávanie kódu aj do detského procesu, je nutné do súboru .gdbinit (nachádzajúci sa v adresári v ktorom sú zdrojové kódy a spustiteľné súbory serveru) zapísať nasledujúci príkaz:
set follow-fork-mode child
Dôležitou otázkou však stále zostáva ako nájsť zraniteľnosť. Postup môžeme zhrnúť do nasledujúcich krokov:
Dokumentácia
Pri zadaní sa bude okrem funkčnosti exploitu primárne hodnotiť kvalita dokumentácie. V dokumentácii je nutné popísať nasledujúce body:
Okrem dokumentácie treba odovzdať aj skript s exploitom.
Deadline
6.4. 2020 15:00
Bonus
V implementácii HTTP servera sa nachádza viacero zraniteľností. Za každú ďalšiu ktorú nájdete (okrem tej, ktorú budete exploitovať) môžete získať bonusový bod. Bonusový bod sa uzná iba v prípade, ak implementujete PoC exploitu, v ktorom však stačí ak ukážete, že dokážete prevziať kontrolu nad tokom programu (prepísať RIP alebo smerník na funkciu), t.j. netreba riešiť žiadny shellcode, stačí vedieť prepísať adresu.
GDB príkazy
V tejto sekcii uvádzame najčastejšie príkazy, ktoré sa môžu zísť počas ladenia servera a vývoja exploitu:
Viac možno nájsť v oficiálnej dokumentácii.